最近学校智能数据处理的作业要求阅读KDD2017,正好可以了解一点机器学习/数据挖掘的东西,简单选了一篇比较有社会影响的文章,发现读起来居然比图形学的paper好懂多了23333。大体来看数据挖掘所涉及到的知识可能还是更偏向于从基础算法出发,数学没有图形学多。不过这篇没有涉及deep learning,如果有哪方面的东西或许情况会有所不同。
言归正传,这是微软亚洲研究院联合摩拜单车发表的一篇用数据驱动解决城市单车道路规划问题的一篇paper。这篇paper背靠摩拜的大量单车数据,提出一种类似于贪心算法的解法。
问题定义和抽象
政府需要对自行车道做出恰当的规划,而自行车道的规划需要综合考虑多方面的因素:
- 预算限制:主要包括政府财政预算以及城市给自行车的余留空间大小
- 便于施工和管理:施工队需要派遣到各个不同的地点铺设自行车道,为了便于管理,通常倾向于使这些车道集合成k个聚类的区域,而不是大面积分散的形式
- 提高自行车的使用率:从政府的角度来说,希望良好规划的自行车道能提高自行车的可用性,以及覆盖更多的区域
这是一个需要考虑诸多方面的复杂问题,而要对这个问题应用算法就必须对这些条件进行抽象,我们考虑整个路面网络图为 $$ G = (V, E) $$
其中V为点集代表道路交叉点,E为边集,代表道路交叉点之间的路段。我们的自行车道规划问题的目标就是找到一个边集的子集 $$ E' $$ 来满足上述的三个条件,这三个条件抽象化即为:
-
每条路段铺设自行车道的经济成本为 $$ e_i.c $$ 而政府的财政总预算为B
所有道路铺设自行车道的经济成本不能超过财政的总预算,即: $$ \sum_{e_i \in E} e_i.c < B $$ 这是限制条件一
-
所有自行车道分成最多k个相关的子区域
$$ C(E') \leq k $$
其中 $$ C(E') $$ 代表集合中聚类的个数
这是限制条件二
-
最大化使用效益
主要有两个目标:
- 促进更多的用户使用自行车,也即用户的覆盖数
- 提高用户的骑行体验,覆盖更多连续的路段(一般来说,骑自行车的人希望能在连续的自行车道上行驶,而不是断断续续的自行车道)
然而这两个目标通常是冲突的,因为用户有不同的骑行路径,因此需要对每个自行车轨道 $$ tr_i $$ 设计一个可伸缩的估价函数 $$ tr_i.g $$ 对这两个目标的不同侧重将影响这个估价函数 $$ tr_i.g = \sum_{s_j \in S_i} {\alpha^{\frac{s_j.l}{min(e.l)}} \times \frac{s_j.l}{min(e.l)}}, \alpha \ge 1 $$ 其中 $$ S_i $$ 是经过轨道的连续片段序列的集合 $$ s_j $$ 是其中的元素 $$ \frac{s_j.l}{min(e.l)} $$ 是对连续片段的长度的度量(以整个网络中最短路段长度为单位,因此这个值不会小于1),这是估价函数中的自变量
在估价函数中 $$ \alpha $$ 就是影响两个目标权重的参数,这个参数越小表面约侧重用户的覆盖数量,越不重视道路的连续性
设计一个指数因子的目的是为了突出连续性的作用,否则这个函数将是线性的,经过最终求和之后(下面将会提到)道路连续性的影响将消除
整个网络的估价函数是每条自行车轨道的估价函数之和 $$ E'.g = \sum_{tr_i \in Tr, tr_i \cap E' \ne \emptyset}tr_i.g $$ 这就是我们的目标函数
这个问题被证明是一个NP-hard问题,证明过程如下:
要证明这个问题是一个NP-hard问题,只要证明这个问题和01背包问题等价即可,我们把每一个路段 $$ e_i $$ 视为背包中的一项,这个路段的经济成本以及空间成本视为这一项占据的空间,将要铺设自行车轨道的集合视为背包,其具有最大为B的空间(财政预算以及道路空间),当 $$ \alpha = 1 $$ 的时候,效益函数是一个和其他项无关的量,相当于背包问题中的价格。这样,这个问题就降级成了一个01背包问题。
更详细的证明略去
算法的系统框架
主要分为两步:
-
预处理,主要包括 1)解析GPS点到轨道数据 2) 将轨道映射到路段。3)为路段建立反向索引,这样可以加快基于路段查询轨道的速度
-
贪心网络扩张算法
这一步是整个算法的核心,又分为两步。
- 首先需要寻找到k个贪心网络的起始片段
我们可以直接选择效益函数在top-k高的k个片段作为起始片段。(经过对数据集的研究,发现在共享单车轨迹起点密集处一般分布在在像大型商场这样离地铁较远的地方,被称为空间热点,而往往效益函数高的地方就在这些空间热点附近)
这种方法非常直接而简单,但是,top-k高的片段往往容易集中在一起,不能很好的扩张,因此,我们采用自下而上(其实自上而下应该也是可以的)的 hierarchical spatial clustering (层次空间聚类)来帮助选出最合适的贪心网络 起始点。
层次空间聚类和K-means不同,它在确定的层级总会产生稳定的结果。为了简化计算,我们首先还是需要筛选出那些效益函数排名较高的路段,作为聚类的基本元素
接下来执行层次空间聚类算法,它每次都合并距离最近的两个聚类。由于这里明显用的是欧式距离,因此我们可以把聚类的中心点作为簇的位置来计算欧式距离。执行这个算法得到k个聚类,再从每一个聚类中选择效益函数最高的路段,这样我们就能得到更加“均匀分布”的贪心网络起始点。
2) 进行贪心网络扩张
到了这一步其实就比较简单了,我们对每一个子网络同步进行扩张,每次寻找和网络邻接的rank 最高的路段加入网络,直到满足下面条件的一个:
- 所有候选路段都已加入某一个网络
- 预算被使用完
至此,算法的主体已经阐述完毕
实验和评估
为了有效的评估和验证上述算法,MSRA的研究人员利用摩拜单车在中国上海整整一个月的骑行数据来深度分析自行车轨迹。
上海的城市网络拥有333,766个路口和440,922个路段。而摩拜单车在这个一个月内共有13,063个独立用户使用了3971辆共享单车,骑行了230,303次。
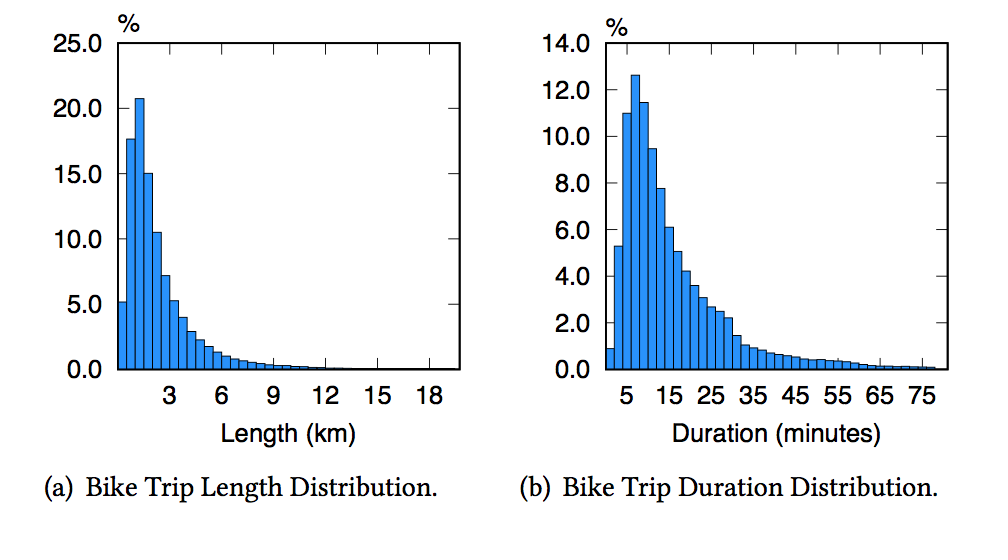
下面两张图图给出了骑行长度和骑行时间的大致分布状况,显然,大部分骑行距离集中在相对较近的路程附近(70%的骑行短于2km),骑行时间也集中于短时。
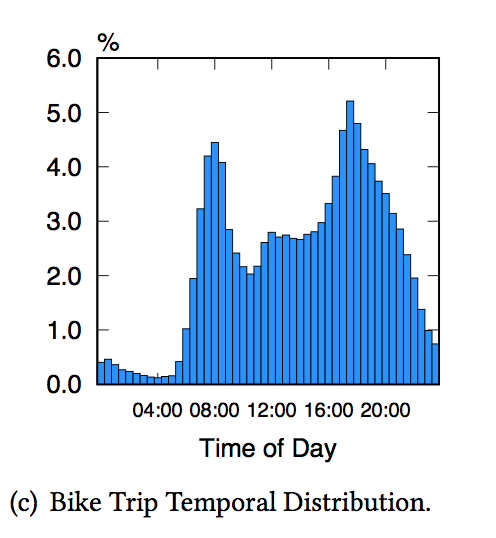
下图给出了开始骑行的时间在一天之间的分布,可以看到在早/晚上下班的“冲刺阶段”是最多人选择使用共享单车的时候
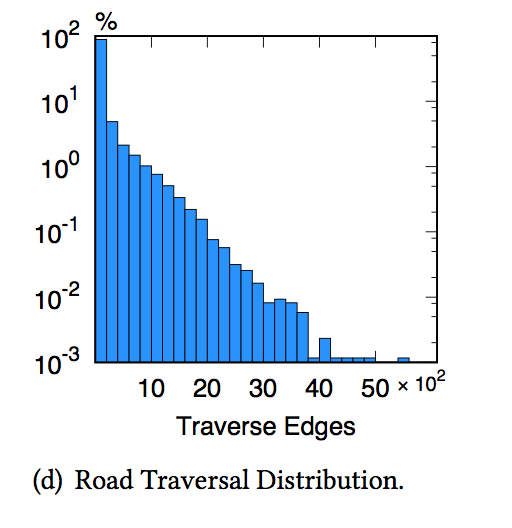
下图反应的则是路段的轨迹数量的分布,这是一个半对数坐标(semi-log)图,其中纵坐标为轨迹数量的对数。大部分路段的骑行轨迹数量小于100,而小部分的路段超过2000,这就证明合理的自行车道规划非常重要
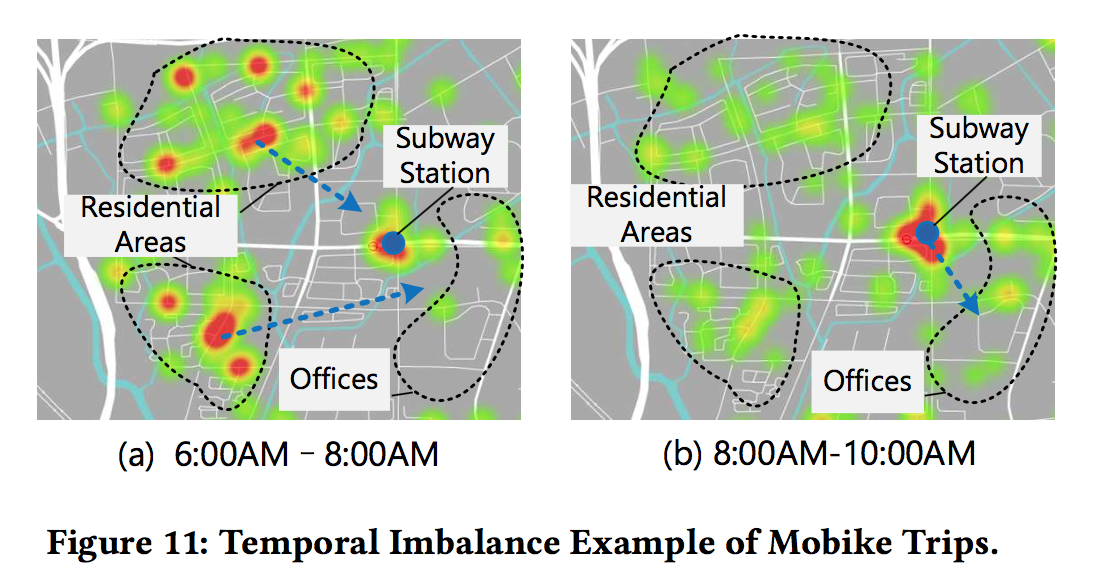
最后是骑行轨迹的空间热点分布图,结合地图来看,大多数骑行从住宅区开始,但在早上8-10点,更多的骑行起点在地铁站
根据实验进行效益评估
在我们的算法中,主要有三个输入参数会明显影响总效益:聚类的个数k,预算B,以及表示对道路连续的重视程度的因子alpha。
对于聚类个数 $$ k $$ 下图给出了这个实验中对不同的k使用hierarchical spatial clustering 和 top-k 对总体效益的比较。
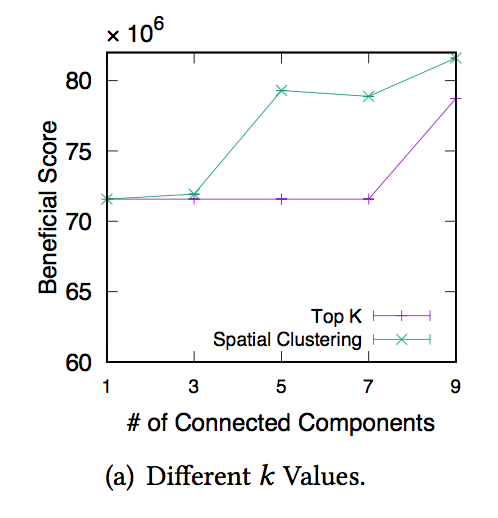
图中显示在 $$ 1 \leq k \leq 9 $$ 这个范围内hierarchical spatial clustering的结果总是更好,并且观察top-k的效益函数发现,当k < 8,总效益不变,这是由于效益高的函数往往集中在一起的缘故。
对于总体预算 $$ B $$ 下图也给出了不同预算在top-k和hierarchical spatial clustering两种策略下对效益的影响。
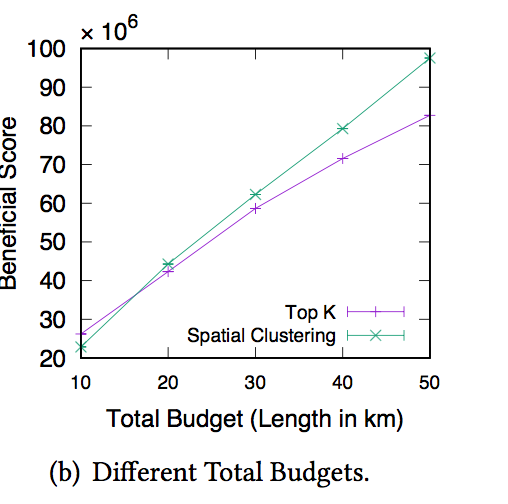
观察发现大的预算下后者更优,当预算较小时反而前者更优,这则是因为当预算较小时把非常有限的轨道铺设在自行车骑行最为频繁的路段可能是更好的策略
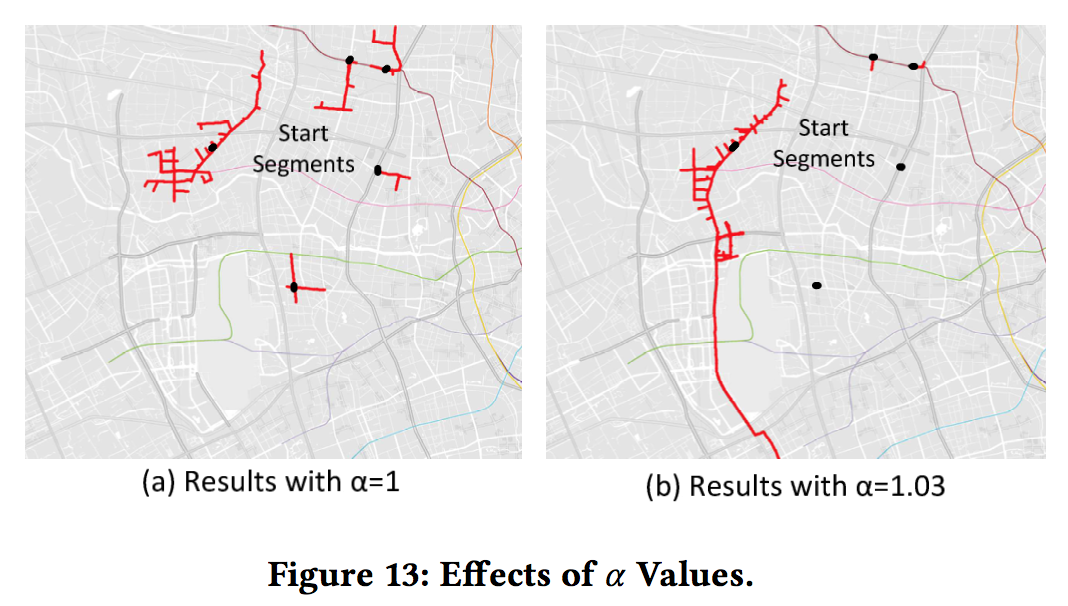
对于因子 $$ \alpha $$ 以下图为例,这个值越大,选择的路段集合就越纵深,越小集合就越分散越短小。
总结
MSRA通过数据驱动的方法为自行车道的设计提供了更科学的参考,不仅如此,他们对实际路段进行了观察,发现在一些算法高度推荐修建自行车道而没有自行车道的地区常常出现自行车混杂在机动车道以及不得不在较多的停车区穿梭的现象,这无疑是危险且不符合好的城市交通建设的。实验和观察证明数据驱动的方法能在有限的预算下寻找到更好的规划方法,并得到了政府的高度评价
声明:本文系个人对原paper的部分翻译和解释,仅作个人学习用途